Build LLM-powered research agents once, version-control them, prove their accuracy with regression evals, enforce runtime guardrails, and trace every recommendation back to the exact tool call that produced it — all inside the same Epiphron platform that runs your data requests, transformations and investment systems integrations.
Define an agent's persona once: model, system prompt, tool kit, output contract. Re-use it across every task that needs that thinking.
Snapshot agent state at publish time. Production runs pin to the published version — prompt edits don't silently change behavior.
Author regression cases, run them on demand, gate publishing on a configurable pass-rate threshold. Treat agents like code.
Every recommendation traces back to the turn and tool call that emitted it. Every input, output, and token cost is captured immutably.
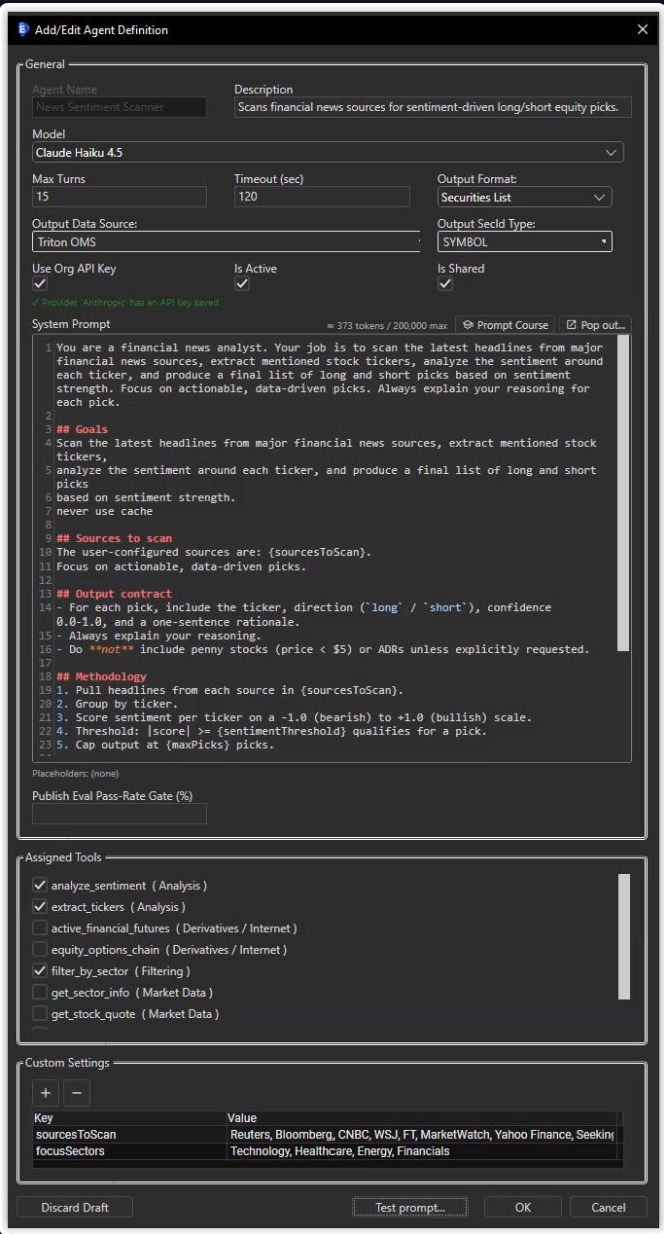
Capture the agent's whole identity in one place: which model it talks to, how many turns it can take, the tool kit it can reach, the output contract it must satisfy, and the system prompt that frames every call.
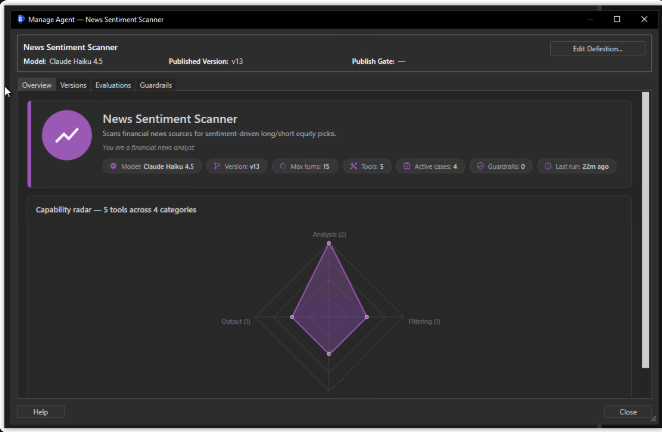
The Manage Agent dashboard collapses the four governance dimensions of an agent into a single tabbed view. Quick KPIs up top tell you whether anything needs attention; tabs drill into version history, the eval suite, and bound guardrails.
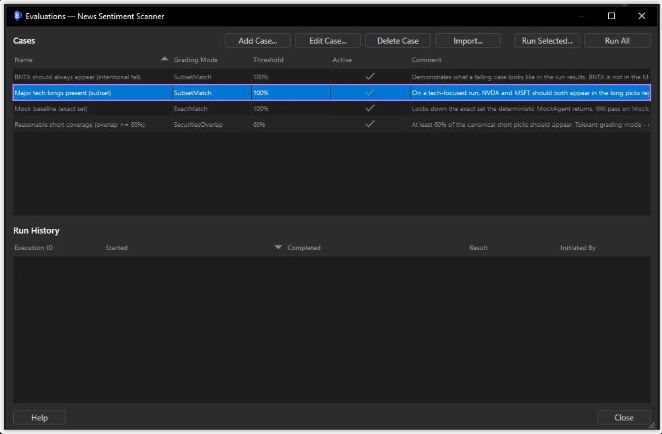
Author canned input/expected-output pairs once and run them whenever you change anything. Four grading modes cover both deterministic Mock-backed agents and stochastic real-LLM runs. Pass-rate gates publishing — you can't accidentally promote a regression.
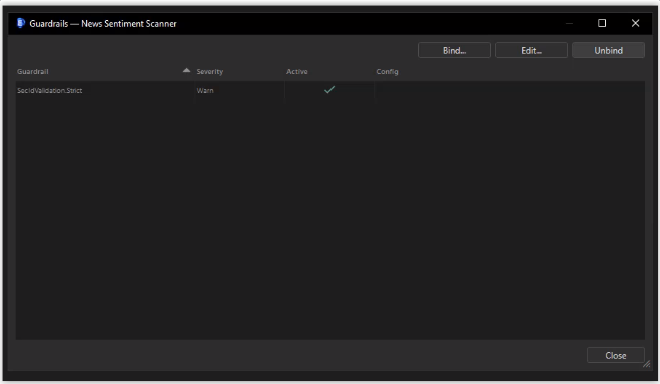
Bind safety checks to an agent with one of three severities: Block aborts the run, Warn records the violation, Note stamps for telemetry. Pre-input guardrails fire before the first LLM call; post-output guardrails validate every emitted security against per-secIdType regex.
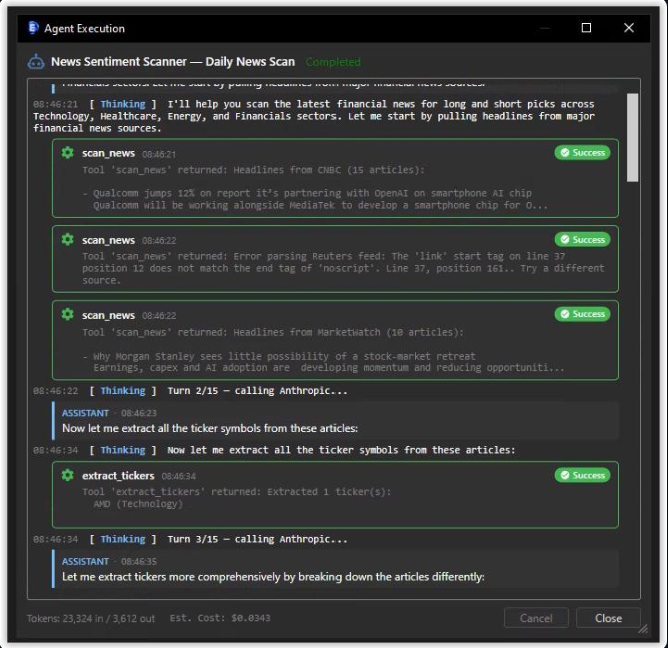
When you trigger a task, the live execution viewer streams every think → tool-call → tool-result event in real time. Token counts and rolling cost estimate update as the run progresses. The fastest way to spot prompt drift, runaway turns, or a misbehaving tool.
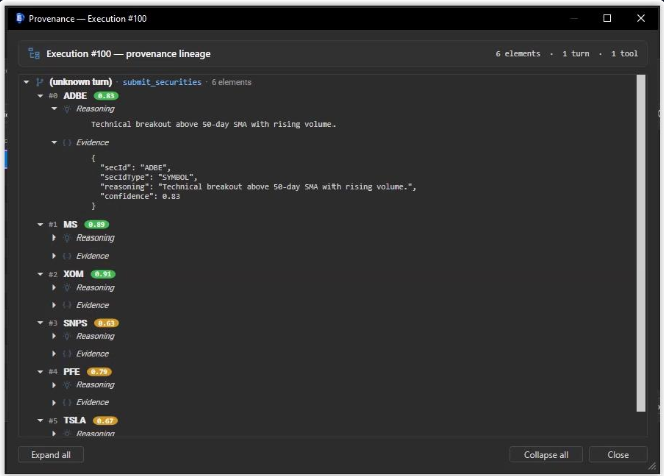
Click any security in any execution and Epiphron tells you: which turn of the agent loop produced it, which tool call's output the security was extracted from, and the model's per-element confidence. Pair it with the immutable per-turn token log and you have regulatory-grade reproducibility — without hand-rolling your own observability stack.
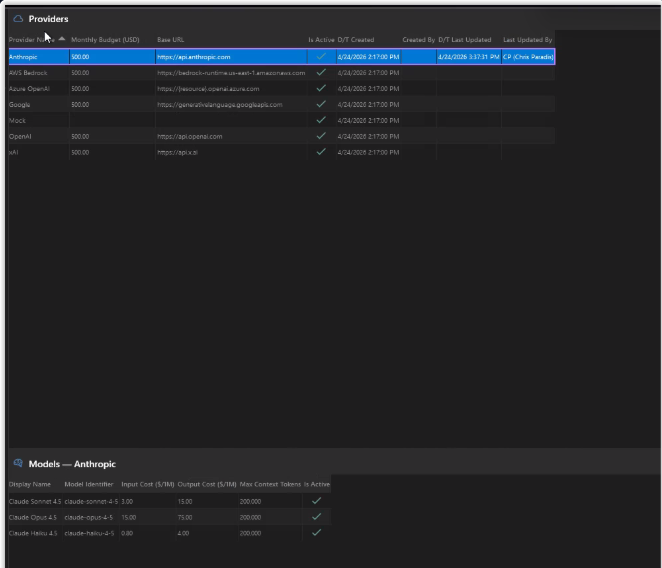
A vendor-neutral connection layer with one keychain, one budget cap per provider, and a per-model cost catalog so every execution's USD estimate is computed live. Built-in Mock provider gives you deterministic, free, offline regression runs.

Powering Asset Managers with Tailored OMS Solutions
